



Hi~ I’m Xinyi, a third-year Ph.D. candidate at University College London (UCL), fortunate to be supervised by Prof. Jing-Hao Xue. Before UCL, I received my master’s degree with honors from Xiamen University (XMU) under the wonderful guidance of Prof. Yang Lu.
I’m currently a visiting student at MBZUAI, fortunate to be supervised by Prof. Zhiqiang Shen, and I’ve truly been enjoying my time in Abu Dhabi. I’ve also been lucky to spend time as a research intern at Westlake University with Prof. Tao Lin, and at Wuhan University with Prof. Mang Ye. I’m especially grateful to my long-term collaborators, Peng Sun at Westlake University & Zhejiang University, Zexi Li at Knowin AI, and Jingyu Lin at Monash University, whose friendship and shared curiosity make research truly wonderful and joyful.
Last but not least, a heartfelt thank-you to my three ragdoll cats, 🍉 (xixi), 🧃 (zhizhi), and 🥥 (yeye), for their unwavering company throughout my Ph.D. journey. 🐾
You can reach me at xinyi.shang.23 [at] ucl.ac.uk, and find my publications on Google Scholar .
🔥 News
- 2026.07: 🎉 One paper is accepted by ACM MM 2026.
- 2026.06: 🎉 Two papers are accepted by ECCV 2026.
- 2026.04: 🎉 Four papers are accepted by ICML 2026.
- 2026.04: 📄 We release a technical report for A Systematic and Comprehensive Analysis of Claude Code. Paper at: [Link]
- 2026.04: 🎉 One paper is accepted by ACL 2026 (main).
- 2026.02: 🎉 Two papers are accepted by CVPR 2026.
- 2025.09: Started as a visiting student at MBZUAI, supervised by Prof. Zhiqiang Shen.
- 2025.02: 🎉 One paper is accepted by CVPR 2025.
- 2025.01: 🎉 One paper is accepted by ICLR 2025.
🎯 Research Interests
My research centers on efficient and generalized deep learning, with recent interests extending to foundation models and generative AI. Numbers in brackets link to the corresponding entries in Publications below.
- Foundation Models & Generative AI. Studying the design and safety of AI agent systems, pushing vision–language understanding to finer-grained semantics, and making generative modeling faster and more scalable.
- Efficient generative modeling: fast, scalable analytical diffusion [3] and one-step generation via duality [4].
- AI agent analysis & defense: understanding Claude Code’s design space [1] and defending against GUI agents via cognitive-gap CAPTCHAs [5].
- Vision–language understanding: semantic, pixel-level image tampering detection [2].
- Efficient Deep Learning. Compressing large datasets into compact, informative subsets, and identifying which data most effectively drives training efficiency.
- Federated Learning (FL). A privacy-preserving distributed paradigm enabling collaborative model training across devices or organizations without sharing raw data.
- Imperfect global data: addressing long-tailed class distributions [14,13] and limited labeled data [8,6] for improved robustness.
- Personalization: strengthening local-model personalization while preserving global performance [11].
- Generalization & optimization: improving global-model generalization through the lens of training dynamics [12].
📝 Publications
* denotes equal contribution; † denotes corresponding author.
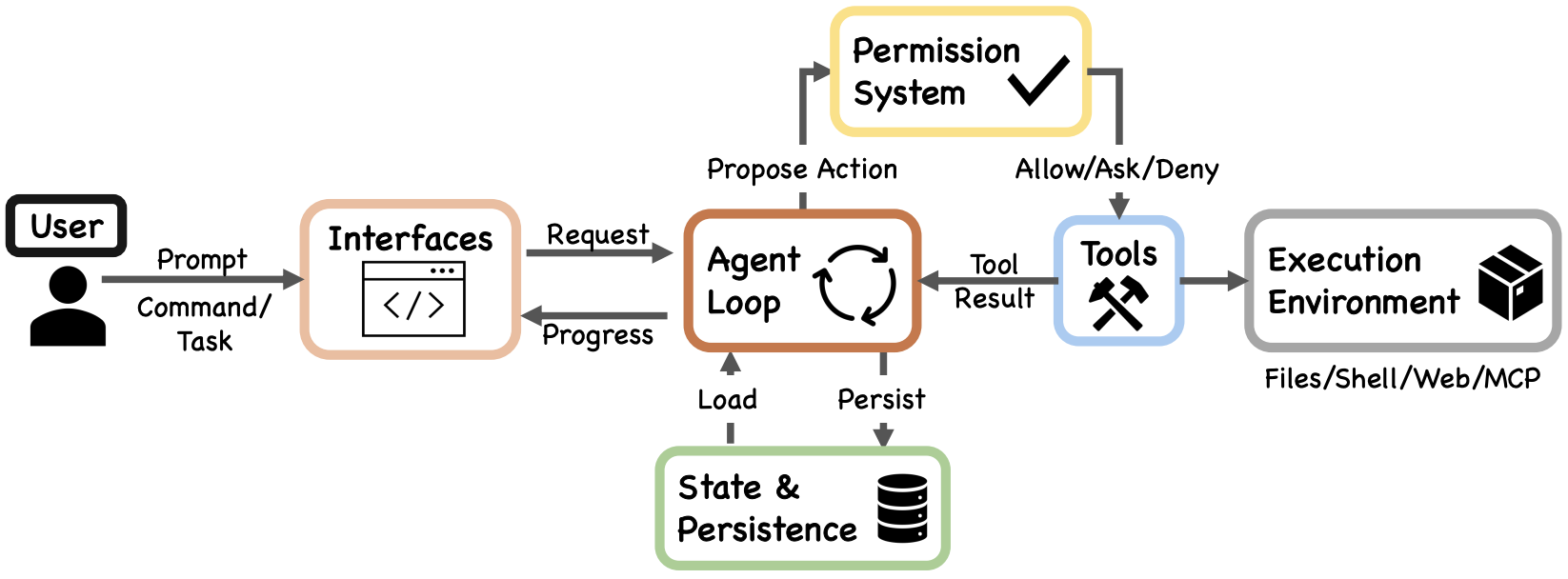
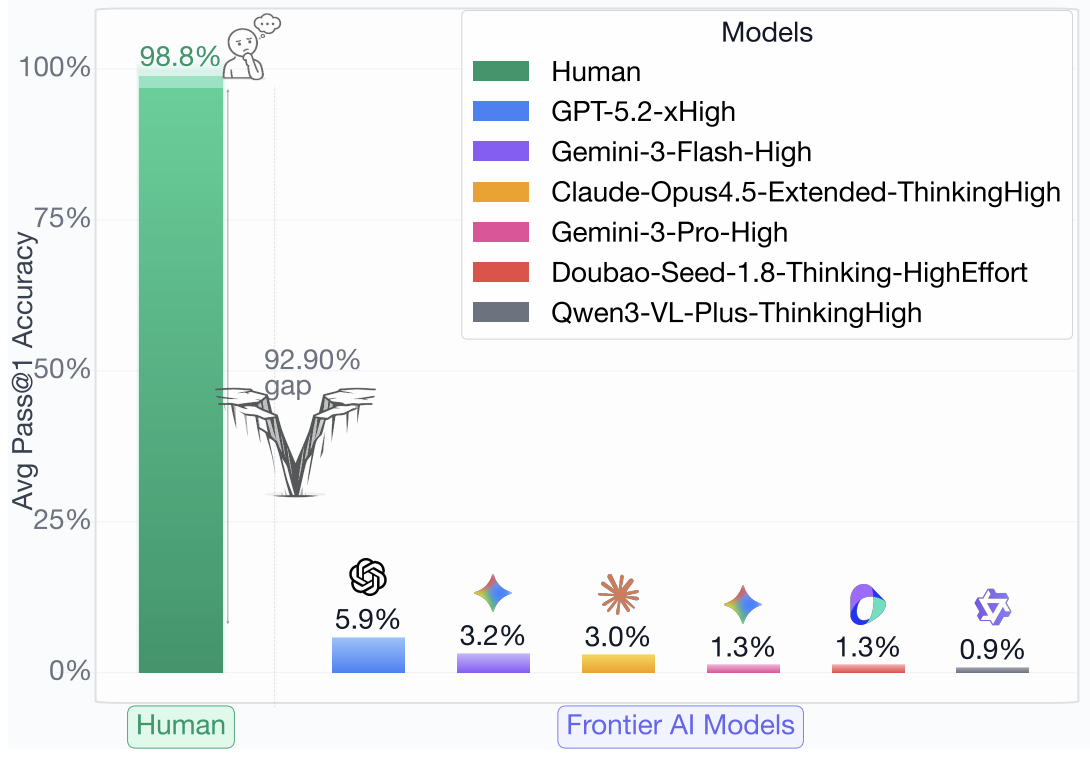
[1] Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems | [code]

Jiacheng Liu, Xiaohan Zhao, Xinyi Shang, Zhiqiang Shen†.
Technical Report, 2026.
- A comprehensive source-level architectural analysis of Claude Code (v2.1.88, ~1,900 TypeScript files, ~512K lines of code), combined with a curated collection of community analyses, a design-space guide for agent builders, and cross-system comparisons.

[2] From Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering | [code]
Xinyi Shang*, Yi Tang*, Jiacheng Cui*, Ahmed Elhagry, Salwa K. Al Khatib, Sondos Mahmoud Bsharat, Jiacheng Liu, Xiaohan Zhao, Jing-Hao Xue, Hao Li, Salman Khan, Zhiqiang Shen†.
arXiv Preprint, 2026.
- We move VLM-based image tampering detection from coarse mask-based annotations to pixel-level detection with semantic understanding, introducing a new taxonomy, benchmark, and evaluation metrics.
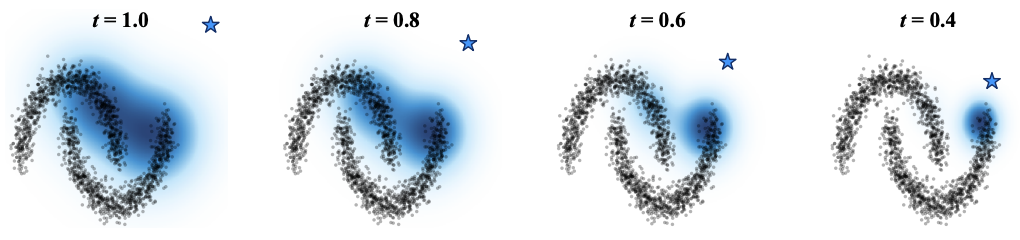
[3] Fast and Scalable Analytical Diffusion
Xinyi Shang, Peng Sun, Jingyu Lin, Zhiqiang Shen†.
arXiv Preprint, 2026.
- GoldDiff dynamically identifies relevant subsets of training data per-timestep, delivering substantial speedups for analytical diffusion and scaling successfully to ImageNet-1K.
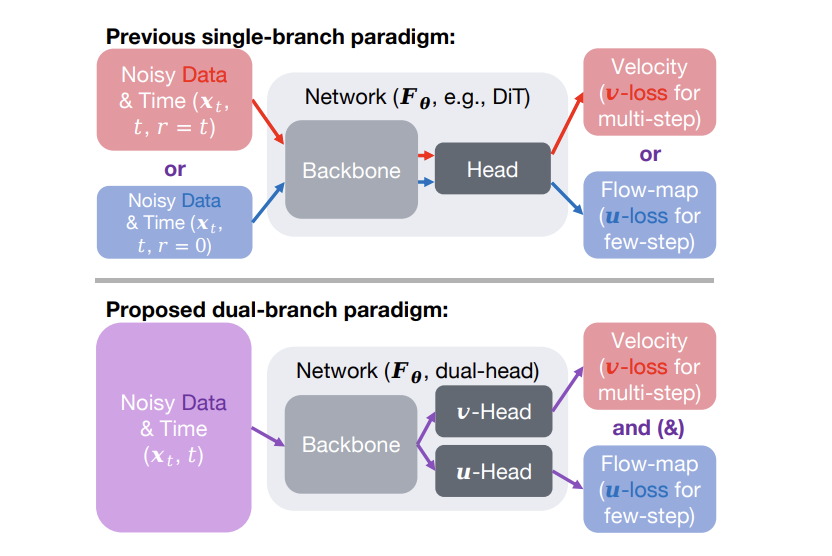
[4] Duality Models: An Embarrassingly Simple One-step Generation Paradigm
Peng Sun, Xinyi Shang, Tao Lin, Zhiqiang Shen.
arXiv Preprint, 2026.
- A one-input-dual-output framework that jointly predicts velocity and flow-map from a shared backbone, enabling efficient two-step image generation with state-of-the-art results on ImageNet 256×256.
[5] Next-Gen CAPTCHAs: Leveraging the Cognitive Gap for Scalable and Diverse GUI-Agent Defense | [code]
Jiacheng Liu, Yaxin Luo, Jiacheng Cui, Xinyi Shang, Xiaohan Zhao, Zhiqiang Shen†.
arXiv Preprint, 2026.
- A scalable CAPTCHA framework that exploits human–AI cognitive gaps to defend against advanced GUI agents via dynamic, adaptive intuitive-reasoning tasks.
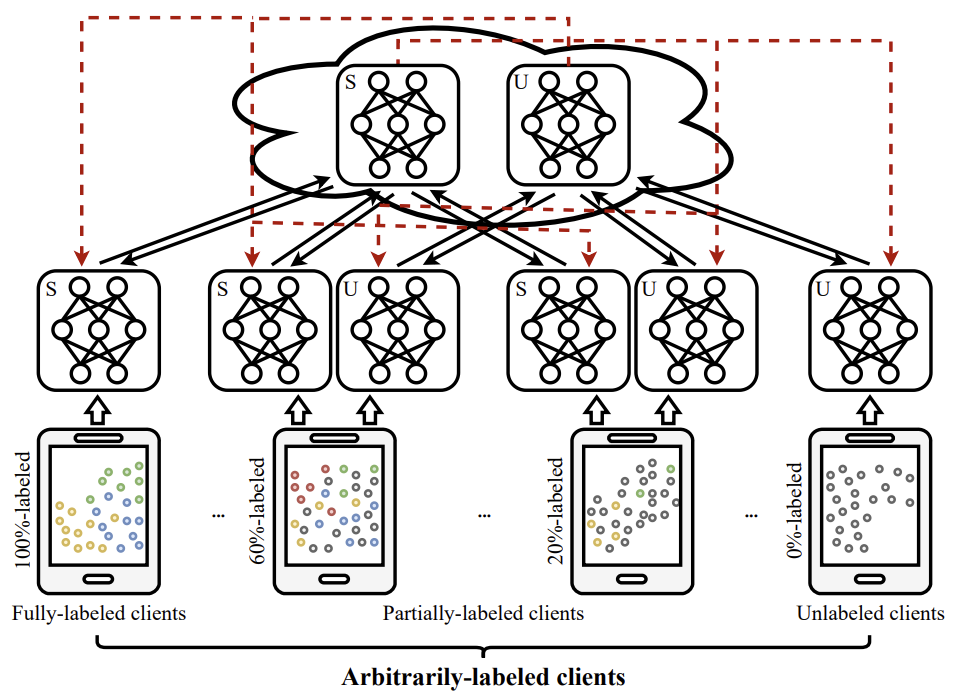
[6] Federated Semi-Supervised Learning with Annotation Heterogeneity
Xinyi Shang, Gang Huang, Yang Lu†, Jian Lou, Bo Han, Yiu-ming Cheung, Hanzi Wang.
IEEE Transactions on Artificial Intelligence (TAI), 2026.
- We formalize Federated Semi-Supervised Learning with annotation heterogeneity and propose a new framework with a mutual-learning strategy.
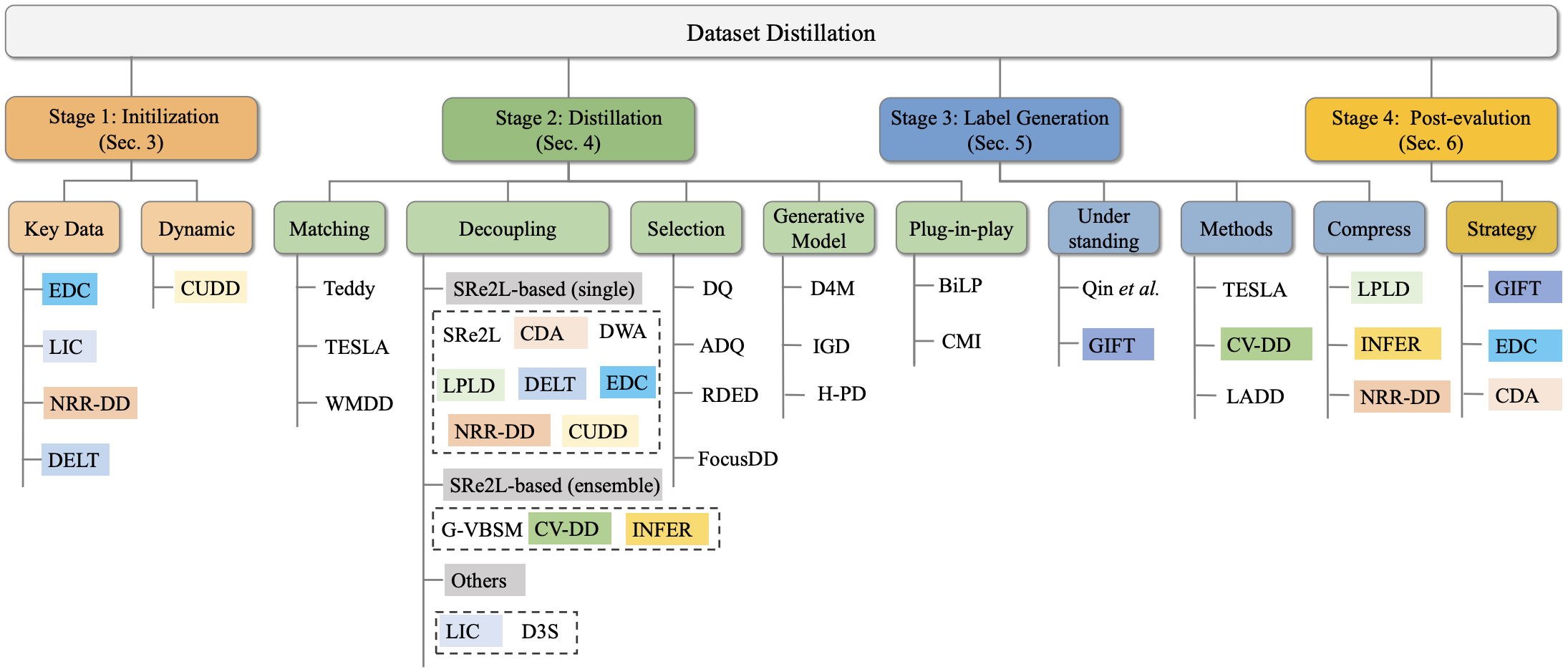
[7] Dataset Distillation in the Era of Large-Scale Data: Methods, Analysis, and Future Directions
Xinyi Shang†, Peng Sun, Zhiqiang Shen, Tao Lin, Jing-Hao Xue.
Preprint, 2025.
- We identify four significant shifts in the field of dataset distillation and provide the first comprehensive, stage-wise review through the dataset-distillation pipeline.
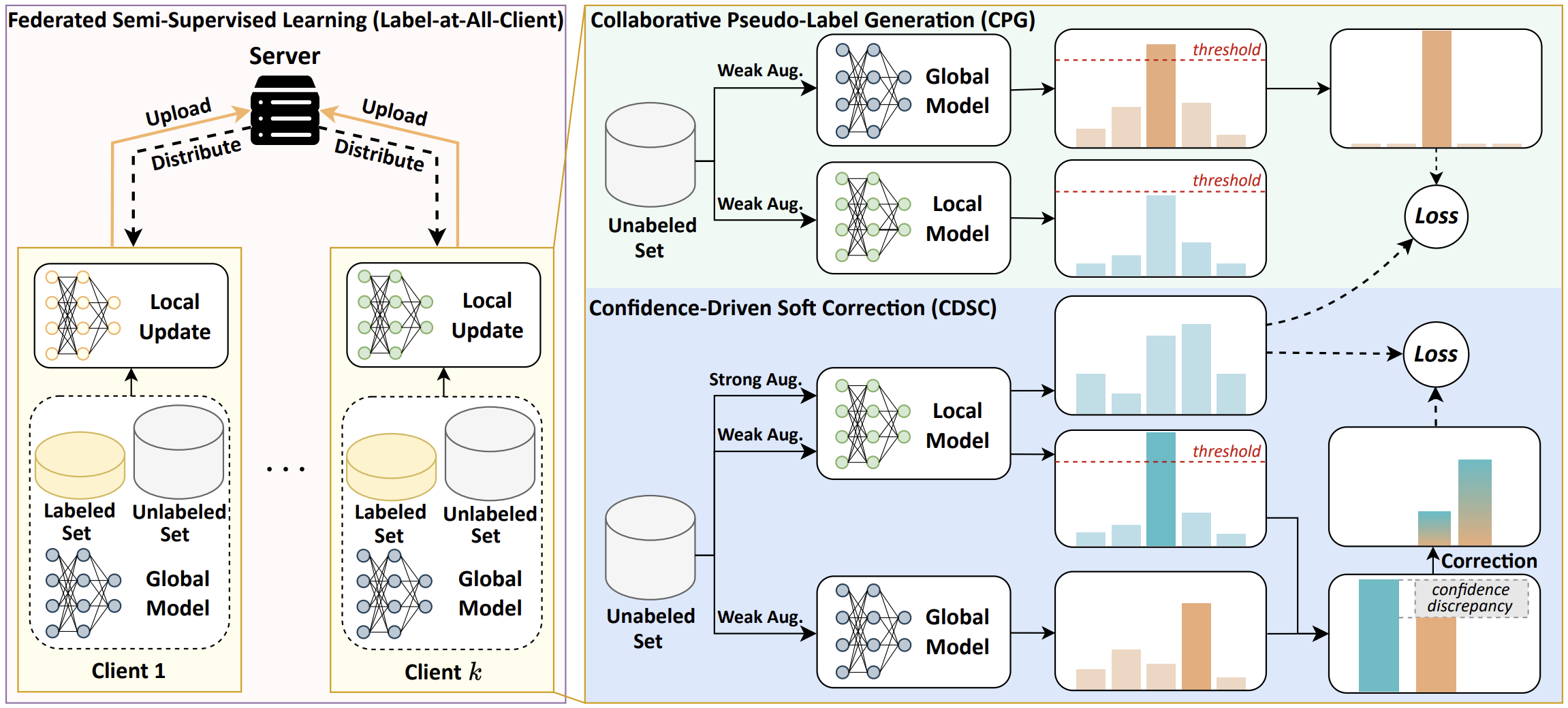
[8] Mind the Gap: Confidence Discrepancy Can Guide Federated Semi-Supervised Learning Across Pseudo-Mismatch | [code]
Yijie Liu, Xinyi Shang, Yiqun Zhang, Yang Lu†, Chen Gong, Jing-Hao Xue, Hanzi Wang.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- We show that (1) data heterogeneity intensifies pseudo-label mismatches, and (2) local- and global-model predictive tendencies diverge with heterogeneity. We propose a simple yet effective method to correct pseudo-labels by exploiting confidence discrepancies.
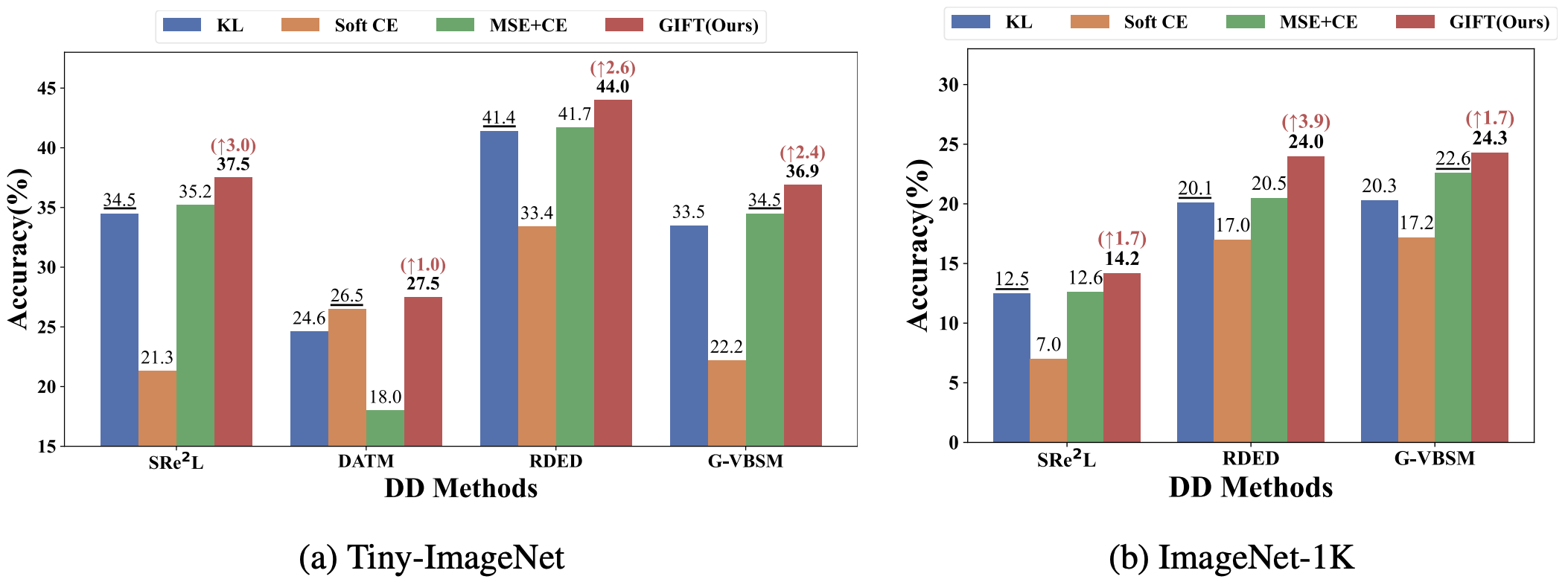
[9] GIFT: Unlocking Full Potential of Labels in Distilled Dataset at Near-zero Cost | [code]
Xinyi Shang*, Peng Sun*, Tao Lin†.
International Conference on Learning Representations (ICLR), 2025.
- Models trained on distilled datasets are highly sensitive to the soft-label loss. Building on this insight, we introduce a plug-and-play approach that efficiently leverages full label information at near-zero cost.
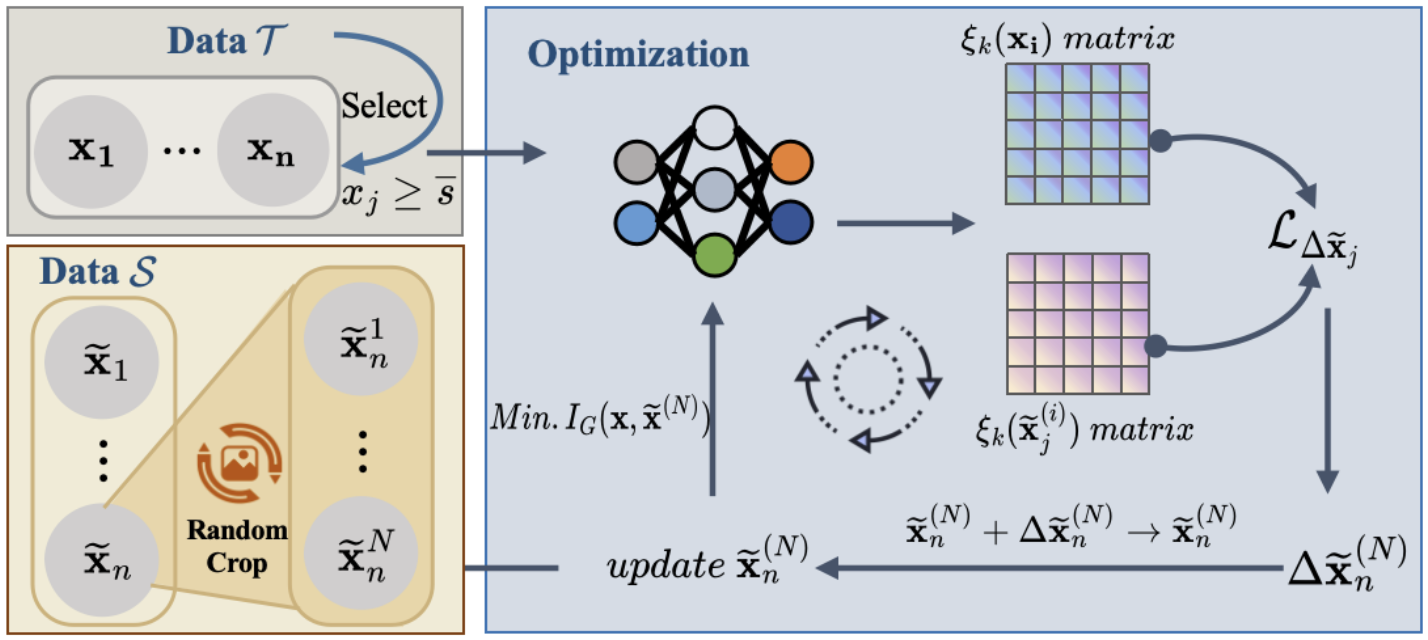
[10] Information Compensation: A Fix for Any-scale Dataset Distillation
Peng Sun, Bei Shi, Xinyi Shang, Tao Lin†.
ICLR Workshop on Data-centric Machine Learning Research (DMLR), 2024.
- A near-lossless information-compression approach that distills the key information of original datasets with minimal loss, surpassing existing methods in both efficiency and effectiveness across dataset scales.
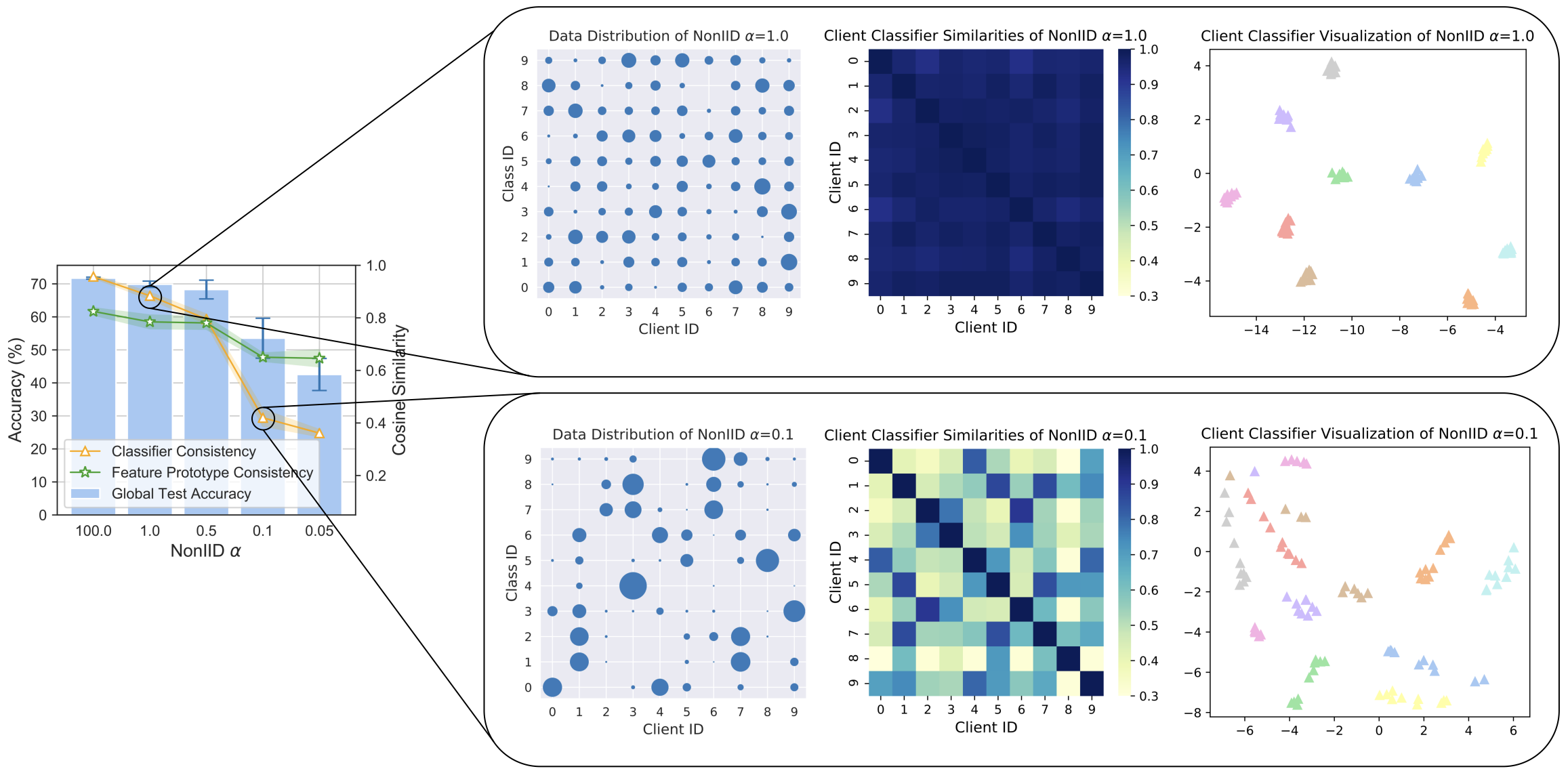
[11] No Fear of Classifier Biases: Neural Collapse Inspired Federated Learning with Synthetic and Fixed Classifier | [code]

Zexi Li, Xinyi Shang, Rui He, Tao Lin†, Chao Wu†.
IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
- A neural-collapse-inspired method that mitigates classifier biases in federated learning, achieving high global-model generalization together with strong local-model personalization.
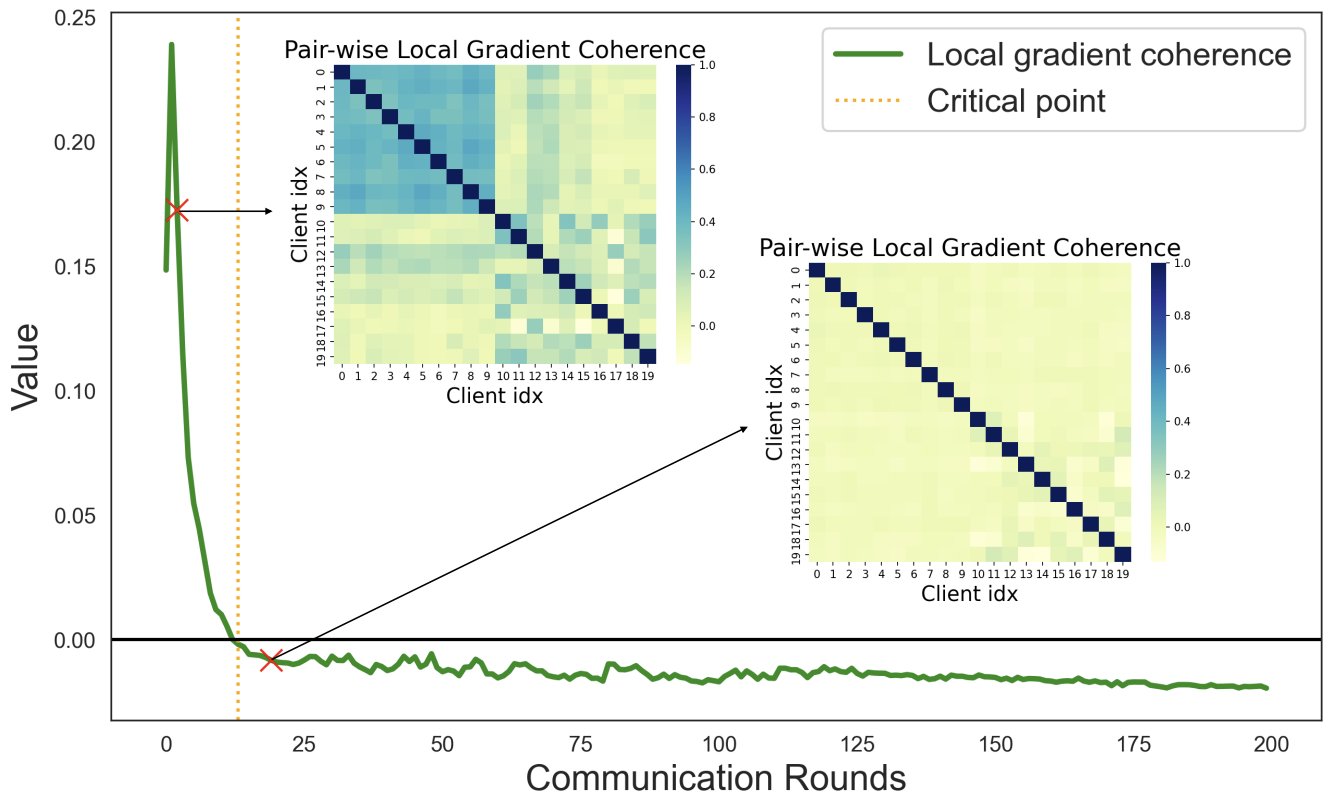
[12] Understanding the Training Dynamics in Federated Deep Learning via Aggregation Weight Optimization | [code]

Zexi Li, Tao Lin†, Xinyi Shang, Chao Wu†.
International Conference on Machine Learning (ICML), 2023.
- We analyze FL training dynamics through client coherence and global weight shrinking, and design an aggregation algorithm that measurably improves generalization.
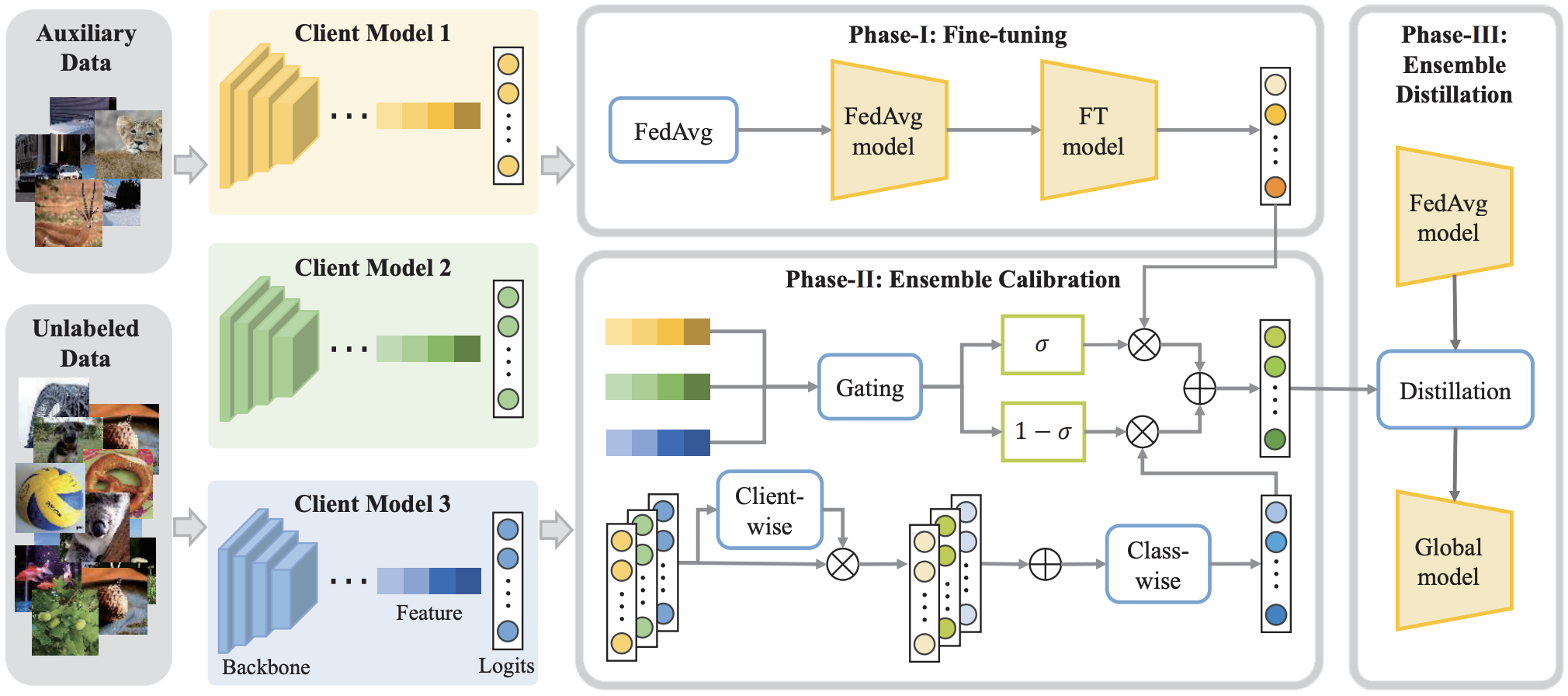
[13] FEDIC: Federated Learning on Non-IID and Long-Tailed Data via Calibrated Distillation | [code]

Xinyi Shang, Yang Lu†, Yiu-ming Cheung, Hanzi Wang.
IEEE International Conference on Multimedia and Expo (ICME), 2022 (Oral).
- A new distillation method with logit adjustment and calibration gating network to solve the joint problem of heterogeneous and long-tailed data.
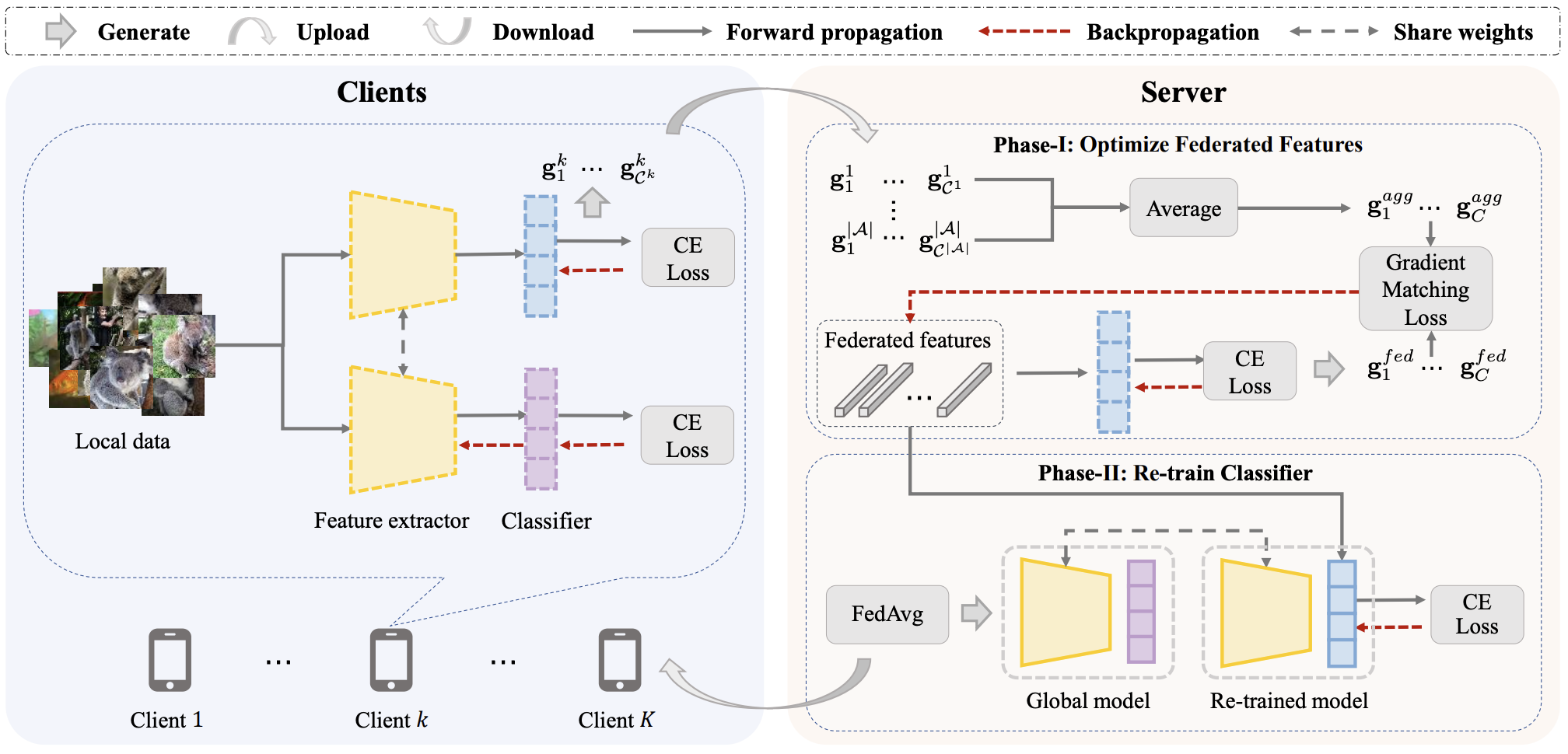
[14] Federated Learning on Heterogeneous and Long-Tailed Data via Classifier Re-Training with Federated Features | [code]

Xinyi Shang, Yang Lu†, Gang Huang, Hanzi Wang.
International Joint Conference on Artificial Intelligence (IJCAI), 2022.
- We first find that the biased classifier is the primary factor behind the poor performance of the global model, then propose CReFF to optimize a small set of learnable features for classifier re-training.
🎖 Honors and Awards
- 2023 Xiamen University Outstanding Master Thesis.
- 2023 Xiamen University Outstanding Graduates.
- 2022 China National Scholarship (Top 0.2%, the highest-level scholarship established by the central government).
- 2022 Excellent Merit Student of Xiamen University (Top 2%).
- 2021 Merit Student of Xiamen University (Top 8%).
- 2020 China College Students Innovation and Entrepreneurship Competition — two provincial projects.
- 2019 Provincial Excellent Volunteer honor (500+ hours of volunteering).
- 2018 Star of Excellent Volunteers honor (only one student in the college per year).
💻 Research Internships
- 2025.09 - Present, VILA Lab, Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), supervised by Prof. Zhiqiang Shen.
- 2022.11 - 2023.09, LINs Lab, Westlake University, supervised by Prof. Tao Lin.
- 2022.06 - 2022.09, MARS Lab, Wuhan University, supervised by Prof. Mang Ye.
🤝 Academic Service
- Conference Reviewer: ECCV 2026, KDD 2026, ICML 2026, CVPR 2026, ICLR 2026, NeurIPS 2025, ICCV 2025, ICLR 2025, CVPR 2025, WACV 2025, IJCAI 2024.
- Journal Reviewer: IEEE TPAMI / TNNLS / TCSVT, ACM Computing Surveys.
🙌 Voluntary Activities
- 2019.03 - 2019.09, Director of Teach For China at Zhongnan University of Economics and Law.
- 2017.09 - 2019.06, Director of We-Bright, supporting 53 rural primary schools across Sichuan and Guangxi provinces.
🎨 Hobbies
- Cooking and Bakery — I hope I will own my bakery one day.
- Drawing.
- Photography and keeping journals.
📸 Journey















